privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff //ArrayList 列表结构被修改的次数 int expectedModCount = modCount; s.defaultWriteObject(); // Write out size as capacity for behavioural compatibility with clone() s.writeInt(size); //对每一对象进行IO流的写处理 // Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); }
if (modCount != expectedModCount) { thrownew ConcurrentModificationException(); } }
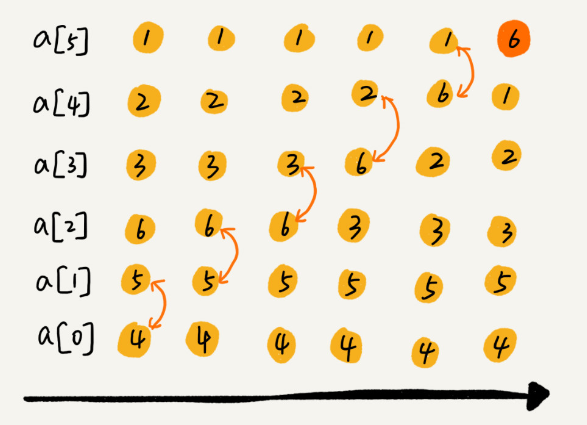
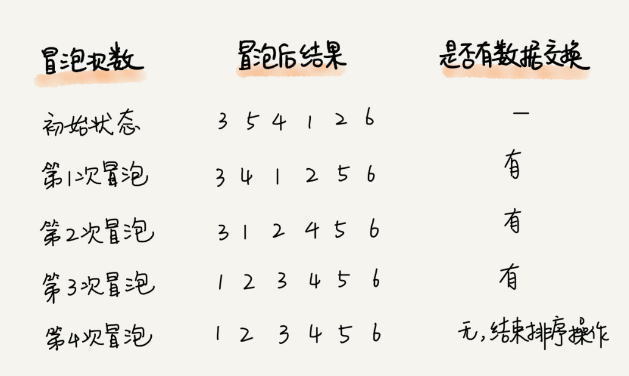
publicvoidbubbleSort(int[] a, int n){ if (n <= 1) return; for (int i = 0; i < n; i++) { boolean flag = false; for (int j = 0; j < n - i - 1; j++) { if (a[j] > a[j + 1]) { int tmp = a[j]; a[j] = a[j + 1]; a[j + 1] = tmp; //冒泡优化,当再一次冒泡中没有进行数据交换时,证明已经是有序数组 flag = true; } } if (!flag) break; }
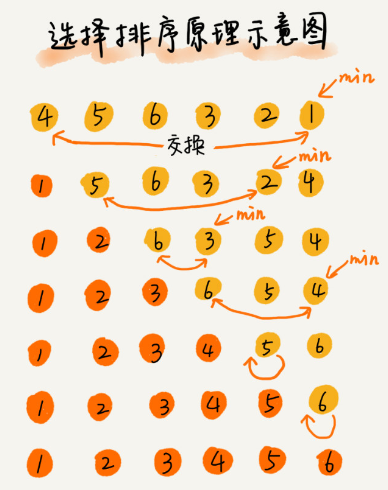
publicvoidselectionSort(int[] a, int n){ if (n <= 1) return; for (int i = 0; i < n - 1; i++) { int min = i; for (int j = i + 1; j < n; j++) { //更新已排序中最小数的下标 if (a[j] < a[min]) min = j; //如果下标发生改变,数据进行交换 if (min != i) { int value = a[min]; a[min] = a[i]; a[i] = value; } } } }
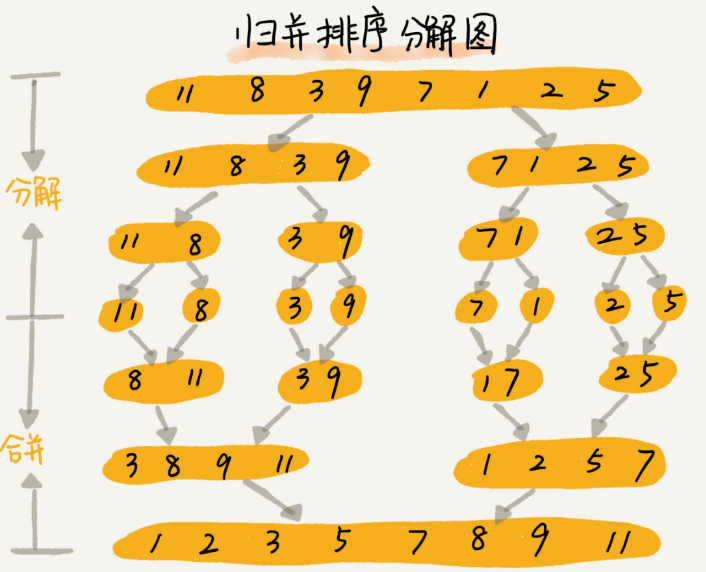
publicvoidmargeSort(int[] a, int n){ marge_Sort(a, 0, n - 1); }
publicvoidmarge_Sort(int[] a, int l, int r){ if (l >= r) { return; } int m = l + ((r - l) >> 1); marge_Sort(a, l, m); marge_Sort(a, m + 1, r); marge(a, l, m, r); }
publicvoidmarge(int[] a, int l, int m, int r){ //申请一个与原数组大小相同的临时数组 int[] tmp = newint[a.length]; int i = l; int j = m + 1; int k = 0; while (i <= m && j <= r) { if (a[i] <= a[j]) { tmp[k++] = a[i++]; } else { tmp[k++] = a[j++]; } } //判断哪个数组有剩余的数据 int start = i; int end = m; if (j <= r) { start = j; end = r; } //将剩余数据拷贝到临时数组 while (start <= end) { tmp[k++] = a[start++]; } //将临时数组中的数据拷贝会原数组,注意边界条件 for (i = 0; i <= r - l; i++) { a[l + i] = tmp[i]; } }